エクセルデータの準備
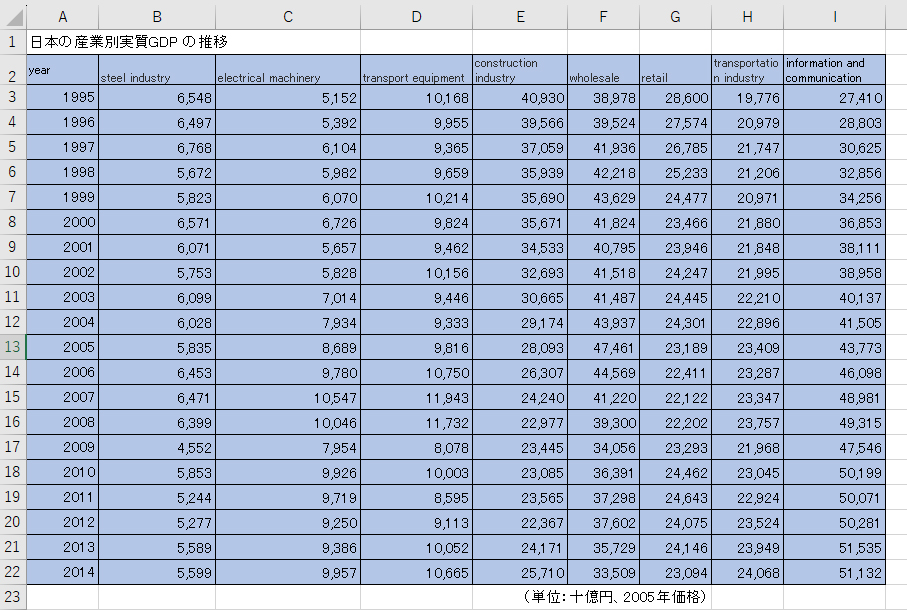
日本の産業別実質GDPの推移のエクセルデータを用意しました。Rで読み込んでいくのは青色のセルのみ読み込んでいきます。詳しくは以前のブログ記事を参考にしてください。

スクリプトは次のとおりです。
library(readxl)
# Excelファイルのパス(ご自身のファイル名と場所に書き換えてください)
file_path <- "F:/ブログ用/17R/関数辞典/04 read_excel/GDP.xlsx"
# read_excel関数のオプションを設定してデータフレームを読み込む
df <- read_excel(
path = file_path,
sheet = "Sheet3", # シート名
range = "A2:I22", # 読み込む範囲
col_types = c("text", rep("numeric",8)), # 列のデータ型を指定
na = "NA", # 欠損値として扱う文字列
skip = 1, # 最初の1行をスキップ
n_max = 50 # 読み込む最大行数
)
dfファイルは次のとおりです。
散布図の行列の作成
散布図の行列を作成するにはpairs関数を使います。
今回の20×9のデータフレームでpairs関数を使用して散布図の行列を作成するには、まずデータフレームから1列目(サンプル名)を除外して、変数のみを含む新しいデータフレームを作成する必要があります。以下に、そのためのRスクリプトを示します。
# サンプル名を除外した新しいデータフレームを作成
df_variables <- df[, -1]新たに作った、df_variablesを見てみましょう。1列目(year)が無くなっているのが確認できます。

準備が整ったのでpair関数を使って散布図の行列を作成しましょう。
スクリプトは次のとおりです。
# 散布図行列の作成
pairs(df_variables)少し時間がかかるかもしれませんが次のようなグラフが出力されます。

カスタマイズ① 変数名を折り返し表示
変数の文字が小さくて見にくいので修正しましょう。
Rのpairs関数を使用して散布図行列を作成する際に、変数名を折り返して表示させることは少し複雑ですが、可能です。
これを実現するためには、カスタムのラベル関数を定義して、pairs関数のlabels引数にそれを渡す必要があります。
以下のステップでカスタムラベル関数を作成し、それをpairs関数で使用します。
- 変数名を折り返すカスタム関数を定義する。
pairs関数のlabels引数にこの関数を適用する。
以下に例を示します。途中からだと分かりづらくなるので、エクセルファイルの読み込みのところから最後までまとめて示します。
library(readxl)
# Excelファイルのパス
file_path <- "F:/ブログ用/17R/関数辞典/04 read_excel/GDP.xlsx"
# read_excel関数のオプションを設定してデータフレームを読み込む
df <- read_excel(
path = file_path,
sheet = "Sheet3", # シート名
range = "A2:I22", # 読み込む範囲
col_types = c("text", rep("numeric",8)), # 列のデータ型を指定
na = "NA", # 欠損値として扱う文字列
skip = 1, # 最初の1行をスキップ
n_max = 50 # 読み込む最大行数
)
# サンプル名を除外したデータフレームを作成
df_variables <- df[, -1]
# 変数名を折り返すカスタム関数
wrap_label <- function(label, width = 10) {
sapply(strsplit(label, " "), function(x) {
paste(strwrap(unlist(x), width = width), collapse = "\n")
})
}
# 散布図行列の作成
pairs(df_variables, labels = wrap_label(colnames(df_variables)))スクリプトを実行すると次のようなグラフが出来ます。
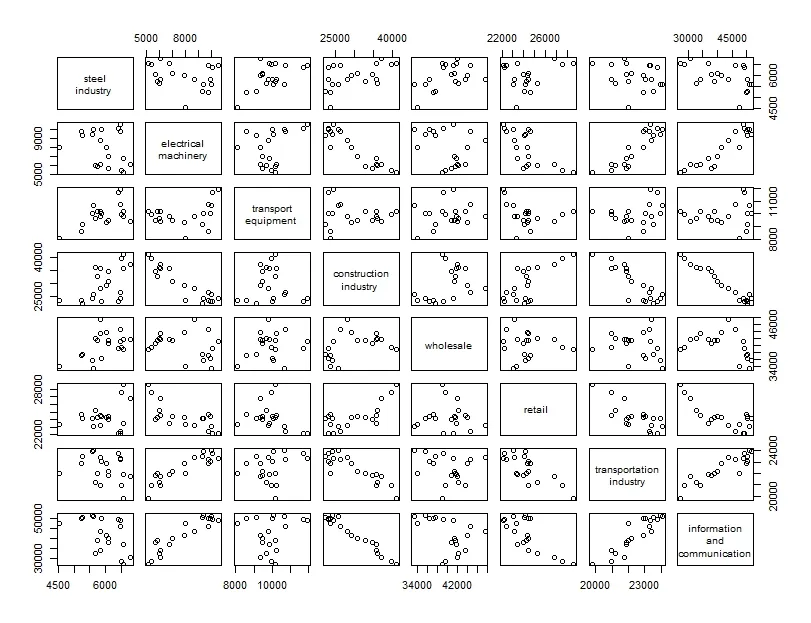
文字がだいぶ見やすくなりました。
カスタマイズ② 回帰直線と相関係数を表示
グラフの見方
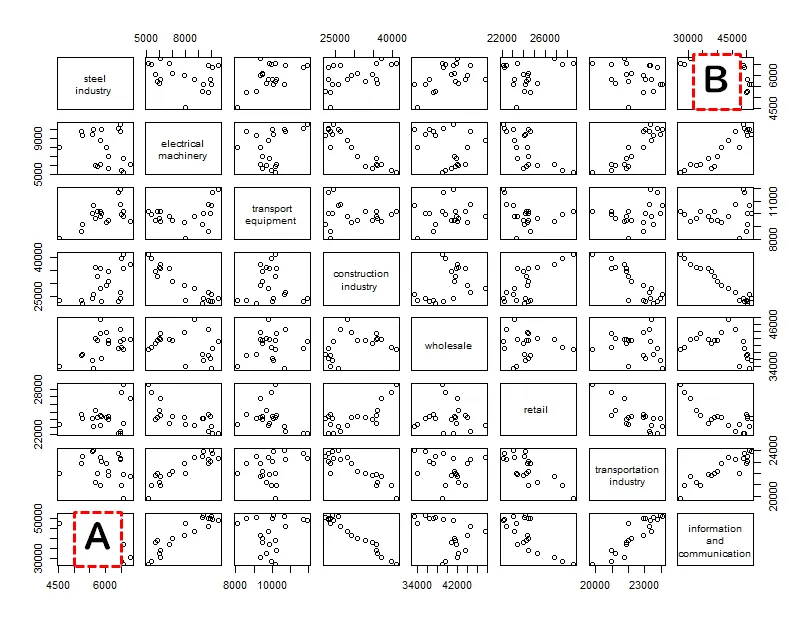
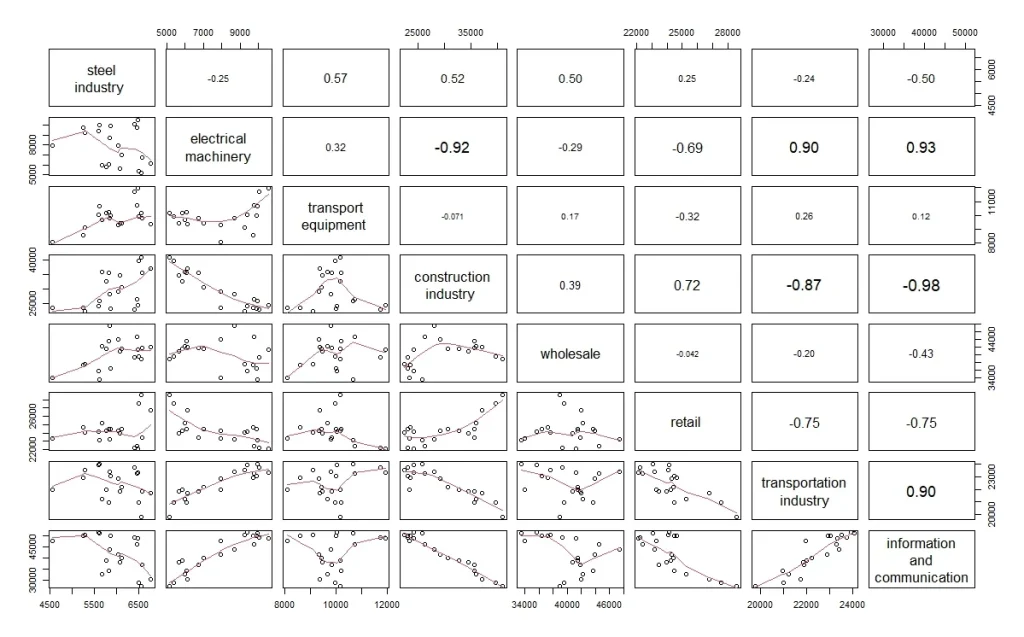
上の写真のAのグラフは、x軸がinformation and communication、y軸がsteel industoryです。
Bのグラフは、x軸がsteel industryでy軸がinformation and communicationです。
結局、AとBの位置のグラフは軸の反転以外は同じグラフになります。
重複したデータを載せるのももったいないので、右上半分には相関係数を表示させるようにしましょう。その方がスペースの有効活用ができます。また、散布図の方には回帰直線を追加して表示するようにしてみたいと思います。
スクリプトを以下に示します。先ほどと同様にエクセルファイルの読み込みから最後まで通して記載します。
library(readxl)
# Excelファイルのパス
file_path <- "F:/ブログ用/17R/関数辞典/04 read_excel/GDP.xlsx"
# read_excel関数のオプションを設定してデータフレームを読み込む
df <- read_excel(
path = file_path,
sheet = "Sheet3", # シート名
range = "A2:I22", # 読み込む範囲
col_types = c("text", rep("numeric",8)), # 列のデータ型を指定
na = "NA", # 欠損値として扱う文字列
skip = 1, # 最初の1行をスキップ
n_max = 50 # 読み込む最大行数
)
# サンプル名を除外したデータフレームを作成
df_variables <- df[, -1]
# 変数名を折り返すカスタム関数
wrap_label <- function(label, width = 10) {
sapply(strsplit(label, " "), function(x) {
paste(strwrap(unlist(x), width = width), collapse = "\n")
})
}
# 相関係数を表示するカスタム関数
panel.cor <- function(x, y, digits=2, cex.cor=0.8, cex.min=0.5) {
usr <- par("usr"); on.exit(par(usr))
par(usr = c(0, 1, 0, 1))
r <- cor(x, y)
txt <- format(c(r, 0.123456789), digits=digits)[1]
# 相関係数の絶対値に基づいてフォントサイズを調整し、最小値を設定
cex.size <- max(cex.cor + abs(r), cex.min)
text(0.5, 0.5, txt, cex = cex.size)
}
# 散布図行列の作成
pairs(df_variables, upper.panel = panel.cor, lower.panel = panel.smooth, labels = wrap_label(colnames(df_variables)))このスクリプトを実行すると次のようなグラフになります。