

散布図にラベルを付けることで、データの意味をより明確にすることができます。このブログ記事では、散布図にラベルを付ける方法を解説します。
散布図に点ラベルを追加するには、ggplot2パッケージのgeom_textまたはgeom_label関数を使用します。これらの関数は、各点にテキストラベルを追加するために使われます。以下に、基本的な使用方法を説明します。
データの準備
mtcarsデータセットはRに組み込まれているサンプルデータです。
mtcarsデータセットの中身を見るには次のようにmtcarsと入力し、実行すると現れます。
mtcarsすると次の様に表示されます。データセットの中身はこのようになっています。
基本的な点ラベルの追加
準備(ggrepelのインストール)
ラベルを付与する前に、付けたラベルの文字が重ならないように自動で調整してくれるggrepel()関数を使うので、事前にggrepelパッケージをインストールし、ライブラリーを呼び出しておいてください。そのためのスクリプトは次のようになります。
install.packages("ggrepel") #パッケージのインストール
library(ggrepel) #ライブラリの呼び出しまず、geom_text_repel関数を使用して、散布図の各点にラベルを追加します。geom_text_repel関数はggrepelパッケージの一部で、テキストラベルが重ならないように自動的に調整する機能があります。
例として、mtcarsデータセットの車名(行名)を各点にラベルとして表示する方法を示します。
ggplot(mtcars, aes(x = wt, y = mpg, label = rownames(mtcars))) +
geom_point() +
geom_text_repel(size = 5, max.overlaps = 5) +
theme_minimal() +
ggtitle("mpg vs. wt") +
theme(
axis.title.x = element_text(size=16), # X軸ラベルのフォントサイズ
axis.title.y = element_text(size=16), # Y軸ラベルのフォントサイズ
axis.text.x = element_text(size=12, family="Helvetica", face="bold"), # X軸数値のフォント
axis.text.y = element_text(size=12, family="Helvetica", face="bold"), # Y軸数値のフォント
plot.title = element_text(size=20, hjust=0.5) # タイトルのフォントサイズと位置
)ここで、sizeはテキストのサイズを、max.overlapsは重なりを許容する最大数を指定します。
スクリプトの解説
ggplotの基本設定
ggplot(mtcars, aes(x = wt, y = mpg, label = rownames(mtcars))): この部分は、ggplot2を使って基本的なグラフ設定を行っています。mtcars: 使用するデータセットです。aes(x = wt, y = mpg, label = rownames(mtcars)):aesはエステティックマッピングを指定します。ここでは、x軸にwt(車の重量)、y軸にmpg(ガソリンのマイル効率)、そして各点のラベルにmtcarsデータセットの行名(車のモデル名)を使用します。
散布図の点をプロット
geom_point(): この関数は散布図の点をプロットします。
テキストラベルの追加
geom_text_repel(size = 5, max.overlaps = 5): ggrepelパッケージのgeom_text_repel関数を使用して、各点にテキストラベルを追加します。
size = 5: テキストのサイズを指定します。max.overlaps = 5: ラベルが重なることを許容する最大数を指定します。
テーマとタイトルの設定
theme_minimal(): グラフのテーマをミニマル(シンプルなデザイン)に設定します。ggtitle("mpg vs. wt"): グラフのタイトルを設定します。theme(...): グラフのさまざまなテキスト要素(軸のタイトル、軸のテキスト、グラフのタイトル)のフォントサイズ、フォントファミリー、スタイル、位置などをカスタマイズします。
注意点
ggrepelは非常に便利ですが、グラフに多くの点がある場合、ラベルがグラフ外に配置されることもあります。- ラベルの数が多すぎると、グラフが読みにくくなる可能性があるため、必要なデータポイントにのみラベルを付けることをお勧めします。
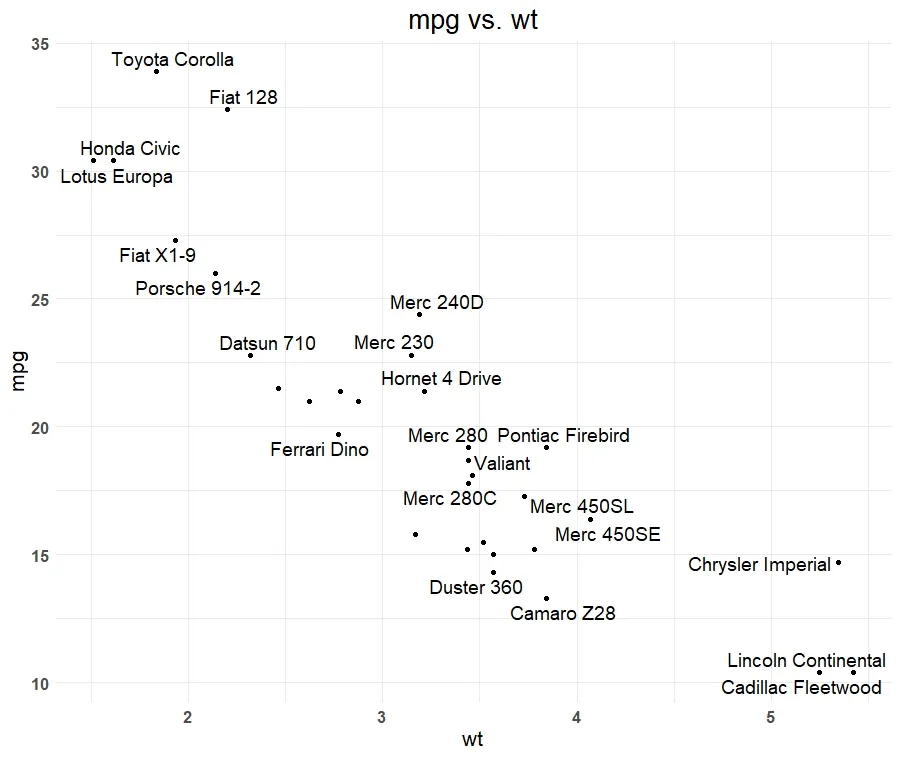
散布図の出力
先ほどのスクリプトを実行すると次のようなグラフになります。
geom_text_repel関数のオプション設定
基本的なオプション
mapping:aes関数を使用して、データのエステティック(例:x, y, label)を設定します。data: 使用するデータフレームを指定します。stat: 使用する統計変換を指定します(デフォルトは"identity")。position: ポジション調整を指定します(デフォルトは"identity")。
テキストとラベルの外観
size: テキストのサイズを指定します。fontface: フォントのスタイル(例:"plain","bold","italic","bold.italic")。family: フォントファミリーを指定します。lineheight: テキストの行の高さを指定します。color: テキストの色を指定します。label.padding: ラベルの周りの余白を指定します(単位は行の高さ)。label.size: ラベルの境界線のサイズを指定します。label.r: ラベルの角の丸みを指定します。label.color: ラベルの境界線の色を指定します。
テキストの配置と重なり
nudge_x: テキストをx方向に微調整します(単位はスケールの単位)。nudge_y: テキストをy方向に微調整します。min.segment.length: ラベルと点を結ぶ線の最小長を指定します。arrow: ラベルから点への矢印を指定します(grid::arrowオブジェクト)。force: テキストを押し出す力の大きさを指定します。max.iter: 位置調整の最大反復回数を指定します。box.padding: テキスト周りの余白を指定します。point.padding: ポイント周りの余白を指定します。
その他のオプション
na.rm: 欠損値を除外するかどうかを指定します(デフォルトはFALSE)。show.legend: 凡例にこのレイヤーを表示するかどうかを指定します。inherit.aes: 親プロットのエステティックを継承するかどうかを指定します(デフォルトはTRUE)。









