

はじめに
散布図は、統計学において二つの連続変数間の関係を視覚的に表現する基本的なグラフの一つです。散布図を描くことによって、データポイントがどのように分布しているか、そして変数間に明確な関係があるかどうかを素早く理解することができます。
R言語では、plot 関数を使って簡単に散布図を作成できます。この関数は、基本的なプロットから始めて、さまざまなオプションを使ってカスタマイズすることができます。Rを用いて散布図を描く具体的な方法について、初心者でも簡単にフォローできるように順を追って説明していきます。
使用するデータの準備
今回は次の様な、身長(height)と体重(weight)のデータが入力されたe、csvファイル(ファイル名はscore.csv)を使用して散布図を描いていきたいと思います。
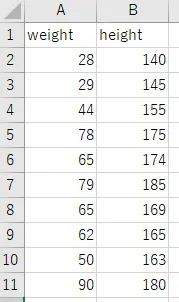
スクリプトの入力
#はじめにデータの読み込みを行います。
df <- read.csv("D:/ブログ用/17R/R/R#5 プロット/plot/score.csv")
#[D:/ブログ用/17R/R/R#5 プロット/plot/score.csv]まではご自身の環境に合わせて変更してください
#サンプルデータをそれぞれ抽出します。
x <- df$weight
y <- df$height
plot(df$weight, df$height,
main="散布図の例", # タイトル
xlab="体重", # X軸のラベル
ylab="身長", # Y軸のラベル
pch=1, # ポイントのタイプ(pch=1は円)
cex=2, #ポイントのサイズ
lwd=2, #ポイントの境界線の太さ
col=rgb(0,0,1,0.5)) # ポイントの色(ここでは半透明の青)スクリプトを実行すると次のようなグラフが出来上がります。
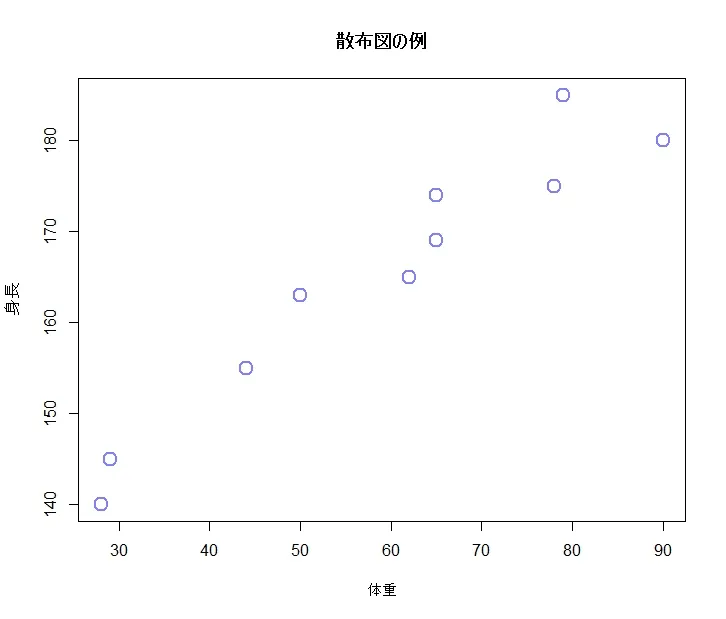
マーカーの設定(pch)の一覧
画像だけでは説明しきれないので注釈をつけます。
pch = 0: 四角形pch = 1: 円pch = 2: 三角形(点が上)pch = 3: プラス記号pch = 4: クロス(×)pch = 5: ダイヤモンドpch = 6: 三角形(点が下)pch = 7: 四角形内に十字pch = 8: 星型pch = 9: 円の中に丸pch = 10: プラスの中に丸pch = 11: 円の中に四角pch = 12: 四角形の中に四角形pch = 13: 円の中に三角(点が上)pch = 14: 円の中に三角(点が下)pch = 15: 四角形(塗りつぶしなし)pch = 16: 円(塗りつぶしなし)pch = 17: 三角形(点が上、塗りつぶしなし)pch = 18: 三角形(点が下、塗りつぶしなし)pch = 19: 固定幅の塗りつぶされた円pch = 20: 固定幅の塗りつぶされた円(より小さい)pch = 21: 囲まれた円(塗りつぶし可能)pch = 22: 囲まれた四角形(塗りつぶし可能)pch = 23: 囲まれた三角形(点が上、塗りつぶし可能)pch = 24: 囲まれた三角形(点が下、塗りつぶし可能)pch = 25: 囲まれたダイヤモンド(塗りつぶし可能)
pch = 21 から pch = 25 までの値は、bg パラメータを使用して背景色を指定できる点が特徴です。それぞれの形状についてのより詳細な情報は、Rのヘルプページを参照してください(コンソールで ?points または ?par と入力)。
rgb関数
Rにおいて、rgb 関数は色を指定するために使用されます。この関数は赤(Red)、緑(Green)、青(Blue)の3つのカラーチャンネルを組み合わせて、指定した色を作り出します。オプションとして透明度(Alpha)も指定することができます。
rgb 関数の基本的な使い方は以下の通りです
rgb(red, green, blue, alpha, names = NULL, maxColorValue = 1)
こで各パラメータは以下のようになります
red,green,blue: これらの値は色の強度をそれぞれ指定し、0からmaxColorValueまでの数値で設定します。maxColorValueのデフォルトは1で、これは色の強度が0(なし)から1(完全な強度)までであることを意味します。しかし、maxColorValueを255として設定することも一般的で、この場合は0から255までの整数を使用して色の強度を指定します。alpha: これは透明度を指定します。値は0(完全に透明)からmaxColorValue(完全に不透明)までで設定します。このパラメータは省略可能ですが、透明度を指定したい場合に有用です。names: オプションで、生成された色に名前を付けることができます。maxColorValue: 色の強度と透明度を指定するための最大値を設定します。デフォルトは1ですが、255に設定することもよく行われます。
例えば、半透明の青色を作りたい場合、以下のように指定することができます(0から1の間で色の強度を指定)
semi_transparent_blue <- rgb(0, 0, 1, 0.5) # 青色の強度が最大で、透明度は50%
もし0から255の値を使いたい場合は、以下のようにmaxColorValueを設定します
semi_transparent_blue <- rgb(0, 0, 255, 128, maxColorValue = 255)
# 同じ色ですが、値の範囲が0から255
rgb 関数で作成された色は、plot や col などの関数で色を指定するパラメータとして使用することができます。
その他の項目の設定コマンド
Rの plot 関数で軸ラベル、メインタイトル、サブタイトルのフォントサイズを変更するには、以下のパラメータを適当な場所(plot()のカッコ内に追加)に入力すると変更できます。
cex.axis: 軸ラベルのフォントサイズを変更します。cex.lab: 軸のタイトルのフォントサイズを変更します。cex.main: メインタイトルのフォントサイズを変更します。cex.sub: サブタイトルのフォントサイズを変更します。
これらのパラメータは、基準となるテキストサイズの倍率を指定します。デフォルト値は 1.0 ですが、これを大きくすることでフォントサイズを大きくできます。
回帰直線の作成
回帰直線を追加するコマンドは次の通りです。
# 回帰直線を追加
abline(lm(y ~ x), col="red")
# lm()は線形モデルを計算し、ablineはそのモデルに基づいた直線を描きますすると次のように回帰直線が描かれます。
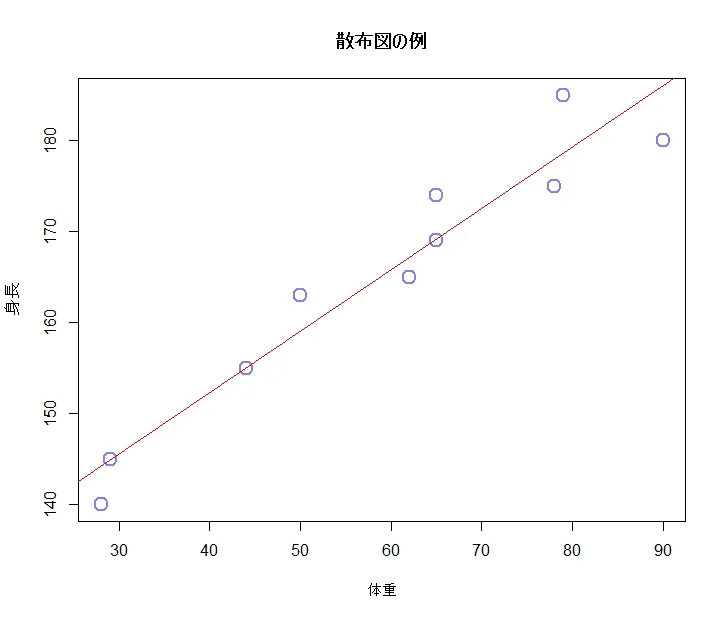
回帰式の表示
回帰式を表示させるスクリプトは以下のとおりです。
model <- lm(y ~ x)
intercept <- coef(model)[1] #y軸切片を抽出
slope <- coef(model)[2] #傾きを抽出
# 回帰式のテキストを作成
eqn <- paste("y = ", round(intercept, 2), " + ", round(slope, 2), "x", sep = "")
# グラフにテキストとして回帰式を追加
text(x = mean(x), y = max(y), labels = eqn, pos = 4)R言語において、sep は "separator" の略であり、特定の関数内で文字列を結合する際に使用される区切り文字を指定するための引数です。
-
x = mean(x): テキストを配置するX軸の位置を指定しています。ここではxの値の平均をX軸の位置として使用しています。つまり、プロットされたデータのX軸に沿った中心点にテキストを配置したいという意図があります。 -
y = max(y): テキストを配置するY軸の位置を指定しています。こちらはyの値の最大値をY軸の位置として使用しており、データの中で最も高いポイントの高さにテキストを配置することを意味しています。 -
labels = eqn: 表示するテキストの内容を指定しています。eqnは通常、文字列や数式を含む変数で、このコマンドの前の部分で定義されていることが期待されます。たとえば、線形回帰分析から導き出された方程式をeqnという変数に保存し、それをグラフ上に表示させることが一般的です。 -
pos = 4: テキストの位置を具体的に指定しています。posは、テキストを指定した座標点に対してどの位置に配置するかを決定する引数です。値の4はテキストを指定した座標の右側に配置することを意味します。
スクリプトを実行すると以下のようにグラフに回帰式が記載されるようになりました。
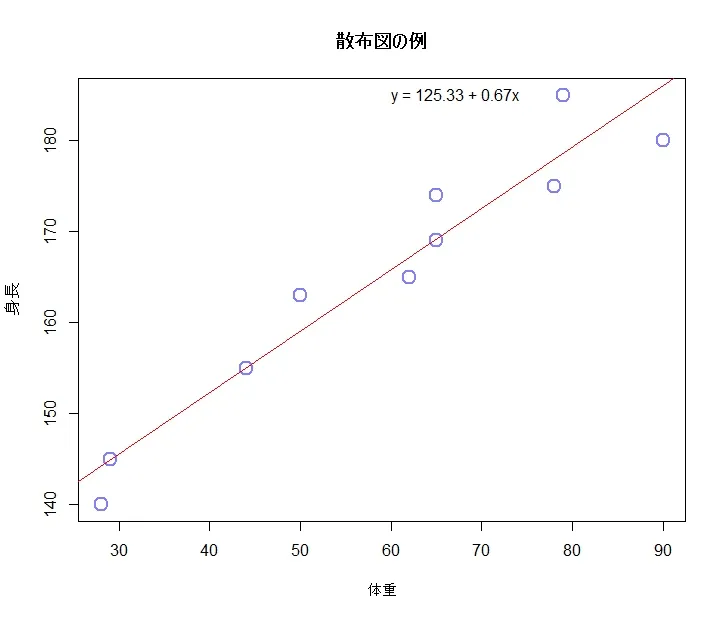
R言語における pos 引数は、テキストをプロット上の特定の位置に配置する際に使われます。この引数は text 関数や mtext 関数などで見られ、テキストがプロット上のどの位置に表示されるかを決定します。
text 関数の場合、pos 引数には以下の数値を指定することができます:
1: 下2: 左3: 上4: 右
決定係数R2乗値の表示
決定係数R2をグラフに表示させるスクリプトは以下のとおりです。
# モデルの要約から情報を取得
summary_model <- summary(model)
r_squared <- summary_model$r.squared # R^2
# R^2のテキストを作成
r_squared_text <- paste("R^2 =", round(r_squared, digits = 2))
# グラフにテキストとしてR^2を追加
text(x = mean(x), y = max(y) - diff(range(y))/20, labels = r_squared_text, pos = 4, cex = 1)このスクリプトでは、lm 関数を用いて線形モデルをフィットさせ、summary 関数でモデルの要約を取得し、そこから 値を取得しています。
text 関数はテキストをグラフに追加するために使用されており、pos = 4 はテキストを指定した座標の右側に配置します。cex = 1 はテキストのサイズを指定するためのものです。
text 関数を2回呼び出しているのは、回帰式と 値を異なる行に表示するためです。2つ目の text 関数では y 座標から diff(range(y))/20 を引いているので、最初のテキストより少し下に表示されます。これにより、テキストが重ならずにきれいに表示されます。
スクリプトを実行すると以下のように表示されるようになります。
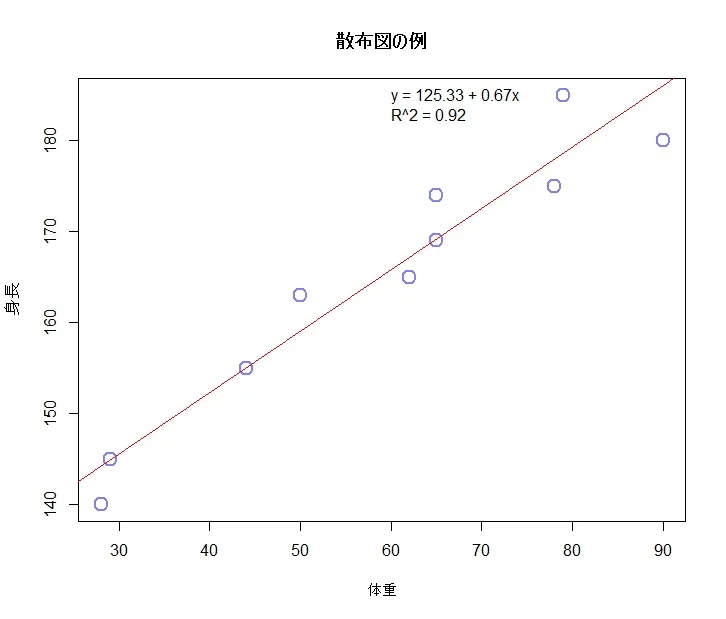
スクリプトまとめ
#はじめにデータの読み込みを行います。
df <- read.csv("D:/ブログ用/17R/R/R#5 プロット/plot/score.csv")
#サンプルデータをそれぞれ抽出します。
x <- df$weight
y <- df$height
plot(df$weight, df$height,
main="散布図の例", # タイトル
xlab="身長", # X軸のラベル
ylab="体重", # Y軸のラベル
pch=1, # ポイントのタイプ(pch=19は円)
cex=2,
lwd=2,
col=rgb(0,0,1,0.5)) # ポイントの色(ここでは半透明の青)
# 回帰直線を追加
abline(lm(y ~ x), col="red") # lm()は線形モデルを計算し、ablineはそのモデルに基づいた直線を描きます
model <- lm(y ~ x)
intercept <- coef(model)[1] #y軸切片を抽出
slope <- coef(model)[2] #傾きを抽出
# 回帰式のテキストを作成
eqn <- paste("y = ", round(intercept, 2), " + ", round(slope, 2), "x", sep = "")
# グラフにテキストとして回帰式を追加
text(x = mean(x), y = max(y), labels = eqn, pos = 4)
# モデルの要約から情報を取得
summary_model <- summary(model)
r_squared <- summary_model$r.squared # R^2
# R^2のテキストを作成
r_squared_text <- paste("R^2 =", round(r_squared, digits = 2))
# グラフにテキストとしてR^2を追加
text(x = mean(x), y = max(y) - diff(range(y))/20, labels = r_squared_text, pos = 4, cex = 1)









